Microsoft a publié une étude de recherche qui démontre comment des techniques d’invite avancées peuvent permettre à une IA généraliste comme GPT-4 de fonctionner aussi bien, voire mieux, qu’une IA spécialisée formée pour un sujet spécifique. Les chercheurs ont découvert qu’ils pouvaient faire en sorte que GPT-4 surpasse le modèle Med-PaLM 2 spécialement formé de Google, explicitement formé sur ce sujet.
Techniques d’invite avancées
Les résultats de cette recherche confirment les connaissances que les utilisateurs avancés de l’IA générative ont découvertes et utilisent pour générer des images ou des textes étonnants.
Les invites avancées sont généralement connues sous le nom d’ingénierie des invites. Bien que certains puissent se moquer du fait que l’incitation puisse être si profonde qu’elle justifie le nom d’ingénierie, le fait est que les techniques d’incitation avancées sont basées sur des principes solides et les résultats de cette étude de recherche soulignent ce fait.
Par exemple, une technique utilisée par les chercheurs, le raisonnement en chaîne de pensée (CoT), est une technique que de nombreux utilisateurs avancés d’IA générative ont découverte et utilisée de manière productive.
L’invite de chaîne de pensée est une méthode décrite par Google vers mai 2022 qui permet à l’IA de diviser une tâche en étapes basées sur un raisonnement.
J’ai écrit sur le document de recherche de Google sur le raisonnement en chaîne de pensée qui permettait à une IA de décomposer une tâche en étapes, lui donnant la capacité de résoudre tout type de problèmes de mots (y compris les mathématiques) et de parvenir à un raisonnement de bon sens.
Ces principes ont finalement influencé la manière dont les utilisateurs d’IA générative obtenaient une sortie de haute qualité, qu’il s’agisse de créer des images ou de produire du texte.
Peter Hatherley (profil Facebook), fondateur des suites d’applications Web Authored Intelligence, a loué l’utilité de l’incitation à la chaîne de pensée :
« L’incitation à la chaîne de pensée prend vos idées de départ et les transforme en quelque chose d’extraordinaire. »
Peter a également noté qu’il intègre CoT dans ses GPT personnalisés afin de les surcharger.
L’incitation à la chaîne de pensée (CoT) a évolué à partir de la découverte que demander quelque chose à une IA générative n’est pas suffisant car le résultat sera systématiquement loin d’être idéal.
L’invite CoT sert à décrire les étapes que l’IA générative doit suivre pour obtenir le résultat souhaité.
La percée de la recherche réside dans le fait que l’utilisation du raisonnement CoT et de deux autres techniques leur a permis d’atteindre des niveaux de qualité époustouflants au-delà de ce qui était considéré comme possible.
Cette technique s’appelle Medprompt.
Medprompt prouve la valeur des techniques d’invite avancées
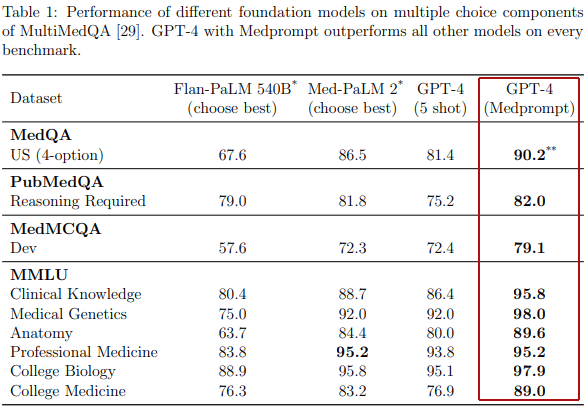
Les chercheurs ont testé leur technique par rapport à quatre modèles de fondation différents :
- Flan-PaLM 540B
- Med-PaLM 2
- GPT-4
- GPT-4 MedPrompt
Ils ont utilisé des ensembles de données de référence créés pour tester les connaissances médicales. Certains de ces tests étaient destinés au raisonnement, d’autres étaient des questions issues d’examens médicaux.
Quatre ensembles de données d’analyse comparative médicale
- MedQA (PDF)
Ensemble de données de réponses aux questions à choix multiples - PubMedQA (PDF)
Oui/Non/Peut-être Ensemble de données d’assurance qualité - MedMCQA (PDF)
Ensemble de données multi-sujets à choix multiples - MMLU (Compréhension massive du langage multitâche) (PDF)
Cet ensemble de données se compose de 57 tâches dans plusieurs domaines contenus dans les thèmes des sciences humaines, des sciences sociales et des STEM (sciences, technologies, ingénierie et mathématiques).
Les chercheurs ont utilisé uniquement les tâches médicales telles que les connaissances cliniques, la génétique médicale, l’anatomie, la médecine professionnelle, la biologie universitaire et la médecine universitaire.
GPT-4 utilisant Medprompt a absolument surpassé tous les concurrents contre lesquels il a été testé sur les quatre ensembles de données médicales.
Le tableau montre comment Medprompt a surpassé les autres modèles de fondation
Pourquoi Medprompt est important
Les chercheurs ont découvert que l’utilisation du raisonnement CoT, ainsi que d’autres stratégies d’incitation, pourrait permettre à un modèle de base général tel que GPT-4 de surpasser les modèles spécialisés formés dans un seul domaine (domaine de connaissances).
Ce qui rend cette recherche particulièrement pertinente pour tous ceux qui utilisent l’IA générative, c’est que la technique MedPrompt peut être utilisée pour obtenir des résultats de haute qualité dans n’importe quel domaine d’expertise, pas seulement le domaine médical.
Les implications de cette avancée sont qu’il n’est peut-être pas nécessaire de consacrer de grandes quantités de ressources à la formation d’un grand modèle de langage spécialisé pour devenir un expert dans un domaine spécifique.
Il suffit d’appliquer les principes de Medprompt pour obtenir un résultat d’IA générative exceptionnel.
Trois stratégies d’incitation
Les chercheurs ont décrit trois stratégies d’incitation :
- Sélection dynamique de quelques plans
- Chaîne de pensée auto-générée
- Mélange de choix
Sélection dynamique de quelques prises de vue
La sélection dynamique de quelques plans permet au modèle d’IA de sélectionner des exemples pertinents pendant la formation.
L’apprentissage en quelques étapes est un moyen pour le modèle fondamental d’apprendre et de s’adapter à des tâches spécifiques avec seulement quelques exemples.
Dans cette méthode, les modèles apprennent à partir d’un ensemble relativement restreint d’exemples (par opposition à des milliards d’exemples), en veillant à ce que les exemples soient représentatifs d’un large éventail de questions pertinentes pour le domaine de connaissances.
Traditionnellement, les experts créent manuellement ces exemples, mais il est difficile de s’assurer qu’ils couvrent toutes les possibilités. Une alternative, appelée apprentissage dynamique en quelques étapes, utilise des exemples similaires aux tâches que le modèle doit résoudre, des exemples choisis dans un ensemble de données de formation plus vaste.
Dans la technique Medprompt, les chercheurs ont sélectionné des exemples de formation sémantiquement similaires à un cas de test donné. Cette approche dynamique est plus efficace que les méthodes traditionnelles, car elle exploite les données de formation existantes sans nécessiter de mises à jour approfondies du modèle.
Chaîne de pensée auto-générée
La technique de chaîne de pensée autogénérée utilise des déclarations en langage naturel pour guider le modèle d’IA avec une série d’étapes de raisonnement, automatisant la création d’exemples de chaîne de pensée, ce qui lui évite de s’appuyer sur des experts humains.
Le document de recherche explique :
« La chaîne de pensée (CoT) utilise des déclarations en langage naturel, telles que « Pensons étape par étape », pour encourager explicitement le modèle à générer une série d’étapes de raisonnement intermédiaires.
Il a été constaté que cette approche améliore considérablement la capacité des modèles de base à effectuer des raisonnements complexes.
La plupart des approches de la chaîne de pensée se concentrent sur le recours à des experts pour composer manuellement des exemples succincts avec des chaînes de pensée pour les incitations. Plutôt que de nous fier à des experts humains, nous avons recherché un mécanisme permettant d’automatiser la création d’exemples de chaîne de pensée.
Nous avons constaté que nous pouvions simplement demander à GPT-4 de générer une chaîne de réflexion pour les exemples de formation en utilisant l’invite suivante :
Self-generated Chain-of-thought Template## Question: {{question}} {{answer_choices}} ## Answer model generated chain of thought explanation Therefore, the answer is [final model answer (e.g. A,B,C,D)]"
Les chercheurs ont réalisé que cette méthode pouvait donner des résultats erronés (appelés résultats hallucinés). Ils ont résolu ce problème en demandant à GPT-4 d’effectuer une étape de vérification supplémentaire.
Voici comment les chercheurs ont procédé :
« L’un des principaux défis de cette approche est que les justifications CoT auto-générées présentent un risque implicite d’inclure des chaînes de raisonnement hallucinées ou incorrectes.
Nous atténuons cette préoccupation en demandant à GPT-4 de générer à la fois une justification et une estimation de la réponse la plus probable à suivre à partir de cette chaîne de raisonnement.
Si cette réponse ne correspond pas à l’étiquette de vérité terrain, nous écartons entièrement l’échantillon, en supposant que nous ne pouvons pas faire confiance au raisonnement.
Bien qu’un raisonnement halluciné ou incorrect puisse toujours donner la bonne réponse finale (c’est-à-dire des faux positifs), nous avons constaté que cette simple étape de vérification des étiquettes agit comme un filtre efficace pour les faux négatifs.
Ensemble de mélange aléatoire de choix
Un problème avec les réponses aux questions à choix multiples est que les modèles de base (GPT-4 est un modèle fondamental) peuvent présenter un biais de position.
Traditionnellement, le biais de position est une tendance qu’ont les humains à sélectionner les meilleurs choix dans une liste de choix.
Par exemple, des recherches ont révélé que si les utilisateurs se voient présenter une liste de résultats de recherche, la plupart des gens ont tendance à sélectionner parmi les meilleurs résultats, même si les résultats sont erronés. Étonnamment, les modèles de fondation présentent le même comportement.
Les chercheurs ont créé une technique pour lutter contre les biais de position lorsque le modèle de base est confronté à une question à choix multiples.
Cette approche augmente la diversité des réponses en éliminant ce que l’on appelle le « décodage gourmand », qui est le comportement des modèles de base comme GPT-4 consistant à choisir le mot ou l’expression le plus probable dans une série de mots ou d’expressions.
Dans le décodage gourmand, à chaque étape de génération d’une séquence de mots (ou dans le contexte d’une image, de pixels), le modèle choisit le mot/phrase/pixel le plus probable (alias jeton) en fonction de son contexte actuel.
Le modèle fait un choix à chaque étape sans tenir compte de l’impact sur la séquence globale.
Choice Shuffling Ensemble résout deux problèmes :
- Biais de position
- Décodage gourmand
Voici comment c’est expliqué :
« Pour réduire ce biais, nous proposons de mélanger les choix puis de vérifier la cohérence des réponses pour les différents ordres de tri du choix multiple.
En conséquence, nous effectuons un mélange de choix et des incitations à l’auto-cohérence. L’autocohérence remplace le décodage naïf à chemin unique ou gourmand par un ensemble diversifié de chemins de raisonnement lorsque cela est demandé plusieurs fois à une certaine température > 0, un paramètre qui introduit un certain degré d’aléatoire dans les générations.
Avec le mélange des choix, nous mélangeons l’ordre relatif des choix de réponses avant de générer chaque chemin de raisonnement. Nous sélectionnons ensuite la réponse la plus cohérente, c’est-à-dire celle qui est la moins sensible au brassage des choix.
Le brassage des choix présente l’avantage supplémentaire d’augmenter la diversité de chaque chemin de raisonnement au-delà de l’échantillonnage de la température, améliorant ainsi également la qualité de l’ensemble final.
Nous appliquons également cette technique pour générer des étapes CoT intermédiaires pour des exemples de formation. Pour chaque exemple, nous mélangeons les choix un certain nombre de fois et générons un CoT pour chaque variante. Nous ne conservons que les exemples avec la bonne réponse.
Ainsi, en mélangeant les choix et en jugeant la cohérence des réponses, cette méthode non seulement réduit les biais, mais contribue également à des performances de pointe dans les ensembles de données de référence, surpassant les modèles sophistiqués spécialement formés comme Med-PaLM 2.
Succès inter-domaines grâce à une ingénierie rapide
Enfin, ce qui rend ce document de recherche incroyable, c’est que les gains ne s’appliquent pas seulement au domaine médical, la technique peut être utilisée dans tout type de contexte de connaissances.
Les chercheurs écrivent :
« Nous notons que, même si Medprompt atteint des performances record sur des ensembles de données de référence médicales, l’algorithme est à usage général et ne se limite pas au domaine médical ou aux réponses à des questions à choix multiples.
Nous pensons que le paradigme général consistant à combiner une sélection intelligente d’exemples en quelques coups, une chaîne d’étapes de raisonnement de pensée auto-générée et un vote majoritaire peut être largement appliqué à d’autres domaines de problèmes, y compris des tâches de résolution de problèmes moins contraintes.
Il s’agit d’une réalisation importante car elle signifie que les résultats exceptionnels peuvent être utilisés sur pratiquement n’importe quel sujet sans avoir à consacrer du temps et de l’argent à une formation intense d’un modèle sur des domaines de connaissances spécifiques.
Ce que Medprompt signifie pour l’IA générative
Medprompt a révélé une nouvelle façon d’obtenir des capacités de modèle améliorées, rendant l’IA générative plus adaptable et polyvalente dans une gamme de domaines de connaissances pour beaucoup moins de formation et d’efforts qu’on ne le pensait auparavant.
Les implications pour l’avenir de l’IA générative sont profondes, sans parler de la façon dont elle peut influencer les compétences en ingénierie rapide.
Lisez le nouveau document de recherche :
Les modèles de fondation généralistes peuvent-ils rivaliser avec les réglages spécialisés ? Étude de cas en médecine (PDF)
Image en vedette par Shutterstock/Asier Romero

